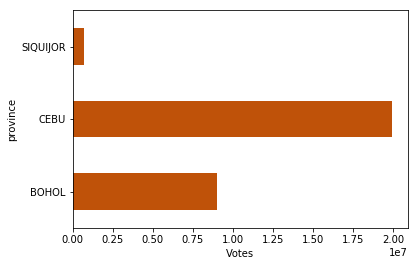Regional Voting Preferences in the 2019 Philippine Senatorial Elections
Looks like voting in the Philippines is all about location, location, location! Literacy and religion may not be factors, but hometown pride definitely is.
python
geospatial
Published
April 17, 2022
Overview
Original creation and submission for this notebook was last May 29, 2019.
This jupyter notebook was created for my Data Mining and Wrangling class for my Masters in Data Science program in the Asian Institute of Management. In particular, this was done during the 2nd semester for a class - Data Mining and Wrangling - as one of the core requirements. In this report, we shall explore and understand the results of the 2019 elections through descriptive statistics. We shall show some exploratory data analysis on the following questions:
How did the various administrative regions of the Philippines voted for their senators?
Is the voter preference homogeneous across the country, or is there a preferred candidate or party per region? More specifically, how does (1) religious affiliation, (2) educational attainment, and (2) sex play a major role on how the voters select their candidates.
Acknowledgements
This analysis was done together with my Lab partner, George Esleta. I would like to thank Prof Christian Alis and the ACCeSS Laboratory for the access to the high-performance computing facility.
Methodology
Pre-requisites: Load Requirement Package
Before anything else, let us first load all important modules for this exercise.
Loading required modules
import osimport ioimport reimport timeimport globimport requestsimport urllib.requestimport numpy as npimport pandas as pdimport geopandas as gpdimport matplotlib.pyplot as pltfrom matplotlib.colors import LinearSegmentedColormapimport seaborn as sns
It is important to identify the datasets we are going to use for this exercise. The two identified datasets the group intends to use are: the 2019 National Data and the 2015-2016 Census data.
With regards to 2019 National data, the team used a web scapper provided Prof. Alis. The web scapper downloaded the election results from the Commission of Elections’ 2019 National and Local Elections website. The results were then stored in a local repository which is then easily accesible for the team. The 2019 elections results are broken down into two main directories: results and contest. In this exercise, the team will explore both directories to map out a comprehensive summary of the 2019 senatorial and party elections.
Secondly, the 2015-2016 Census data has already been stored in a local repository for easier access. One of the main reasons why the team decided to use the 2015-2016 Census data is because of the lack of availability of recent data. The Philippine Statistics Authority only releases a comprehensive census survey ever six years. However for the purpose of this exercise, the team has agreed that the 2015-2016 census data can act as an appproximate for today’s population.
Step 1: Extract and collect the 2019 Elections (Results) data
The first directory to explore is the 2019 Election results. The results directory contains all electoral results from a regional level down to the barangay level. For each level, a specific coc.json file is stored. This file contains all electoral results data and metadata for both national and local elections. However for the purposes of this analysis, we will only look at the aggregated elections data at the regional level. The files that we are interested are the coc.json files associated to each province, as these files contain the metadata and data on the election results.
The main structure of each coc.json file contains the following main keys: vbc, rs, sts, obs, and cos. For the purpose of this exercise, the important key the group needs to extract is the rs key as this provides the each candidate’s total votes per area. Under the rs key, the following keys can be found: cc, bo, v, tot, per, and ser. Cross referencing these keys with official statements and comelec documentations suggests that important keys are as follows: cc pertaining to contest_type, bo pertaining to the candidate_id, and v pertaining to votes_per_province.
Paremeter
Description
cc
Contestant Code
bo
Contestant ID
v
Total Votes Per Contestant
tot
Total Votes Per Province
However, it must be pointed out that the available data only goes as high as provincial data. If we want to process the provincial level, the team will have to aggregate the data up.
The group created utility functions for easier retrieval of the provincial elections datasets. The purpose for the utility functions (and future utility functions) are for initial cleaning and manipulations. This is to ensure each dataset is ready for aggregation.
The get_province_coc method unpacks each key and value from the coc.json dictionary into a cleaned up dataframe. In addition, the method identifies which region and province the file originated from by examining the filepath that was passed.
The get_all_province_coc method is a walker that goes through each of the results directory. The walker checks if the filename has an equal value to coc.json. If a coc.jsonwas located, the get_province_coc method is applied with the filepath as the parameter. The resulting dataframe is then appended to a master dataframe for further extraction and analysis. For this exercise, the group only had to extract data up to the regional and provincial levels so only three wildcard were use for the glob walker.
Special methods (get_ncr_coc and get_all_ncr_coc) were established to get the cities’ coc.json. For the case of the NCR cities, theire associated coc.json files were one directory lower.
Function for get_province_coc()
def get_province_coc(filepath):""" Loads a single coc file. Adds additional columns `region` and `province to the DataFrame, depending on filepath. Parameters ---------- filepath : filepath Return ------ df : a dataframe """ output = []withopen(filepath, 'r') as f: dirpath, filepath = os.path.split(filepath) region = dirpath.split('/')[-2] province = dirpath.split('/')[-1] data = json.load(f)for each in data['rs']: row = [float(element) for element inlist(each.values())] output.append([data['vbc']] + row + [region] + [province]) df = pd.DataFrame(output, columns=['vbc', 'cc', 'bo', 'v', 'tot', 'per', 'ser','region', 'province'])return df
Function for get_all_province_coc()
def get_all_province_coc(tree):""" Loads all province COC files and saves them to a dataframe Checks the filepath if filename is 'coc.json' Created a new column to deal with the reclassification of "NEGROS ORIENTAL" and "NEGROS OCCIDENTAL" to "NIR" to match the PSA 2016 dataset. Parameters ---------- filepath : filepath Return ------ df : a dataframe """ total = pd.DataFrame()forfilein glob.glob(tree):if os.path.basename(file) =='coc.json': df = get_province_coc(file) total = total.append(df) total.rename(columns={'region': 'region_raw'}, inplace=True) total['region'] = total['region_raw'].copy() total.loc[(total['province'] =="NEGROS ORIENTAL") | (total['province'] =="NEGROS OCCIDENTAL"), 'region'] ='NIR'return total
Function for get_ncr_coc()
def get_ncr_coc(filepath):""" Loads a single coc file. Adds additional columns `region` and `province to the DataFrame, depending on filepath. Parameters ---------- filepath : filepath Return ------ df : a dataframe """ output = []withopen(filepath, 'r') as f: dirpath, filepath = os.path.split(filepath) region = dirpath.split('/')[-3] province = dirpath.split('/')[-2] data = json.load(f)for each in data['rs']: row = [float(element) for element inlist(each.values())] output.append([data['vbc']] + row + [region] + [province]) df = pd.DataFrame(output, columns=['vbc', 'cc', 'bo', 'v', 'tot', 'per', 'ser','region', 'province'])return df
Function for get_all_ncr_coc()
def get_all_ncr_coc(tree):""" Loads all province COC files and saves them to a dataframe Checks the filepath if filename is 'coc.json' Parameters ---------- filepath : filepath Return ------ df : a dataframe """ total = pd.DataFrame()forfilein glob.glob(tree):iffile.split('/')[7] =='NCR':if os.path.basename(file) =='coc.json': df = get_ncr_coc(file) total = total.append(df) total.rename(columns={'region': 'region_raw'}, inplace=True) total['region'] = total['region_raw'].copy()return total
With these utility functions inplace, the team can now apply these methods for easier access to the 2019 elections data.
We can now compile all of the election results with the following line:
Compiling provinces data with NCR data
tree ='/mnt/data/public/elections/nle2019/results/*/*/*'ncr_tree ='/mnt/data/public/elections/nle2019/results/*/*/*/*'df_results = get_all_province_coc(tree)df_results = df_results.append(get_all_ncr_coc(ncr_tree))df_results.drop_duplicates(inplace=True)
Let’s see what we have:
vbc
cc
bo
v
tot
per
ser
region_raw
province
region
0
89550
1.0
1.0
2004.0
1708769.0
0.11
2800.0
REGION I
ILOCOS NORTE
1
89550
1.0
2.0
1607.0
1708769.0
0.09
2800.0
REGION I
ILOCOS NORTE
2
89550
1.0
3.0
8772.0
1708769.0
0.51
2800.0
REGION I
ILOCOS NORTE
3
89550
1.0
4.0
1767.0
1708769.0
0.10
2800.0
REGION I
ILOCOS NORTE
4
89550
1.0
5.0
5068.0
1708769.0
0.29
2800.0
REGION I
ILOCOS NORTE
Next, let us examine the obtained dataset with actual election results.
By cross checking the results with Comelec data, we can identify the senators and party names.
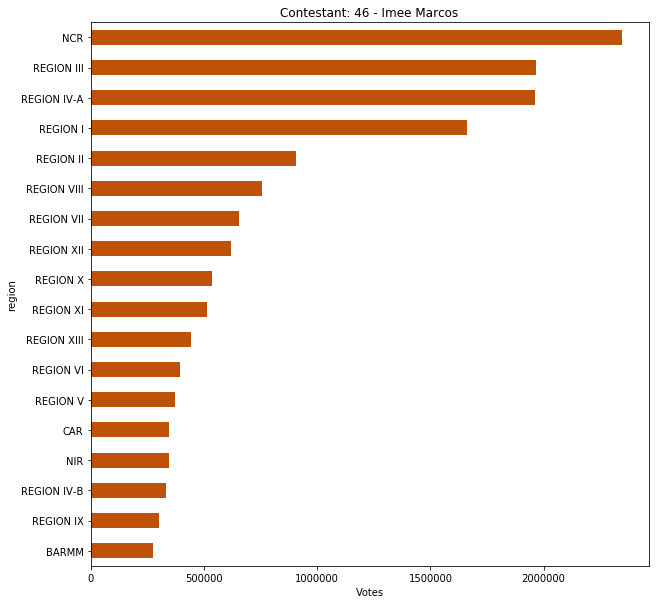
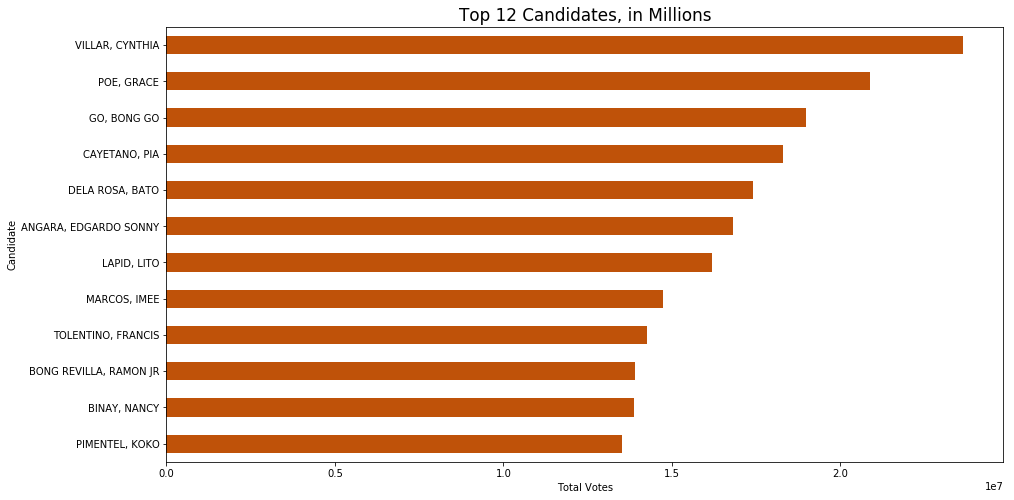
Just to check our data, we can look at an example senator from the dataset. By choosing cc=1 and bo=46, we are actually highlighting Imee Marcos’ senatorial candidacy results.
Code of creating a bar graph for Imee Marcos highest voting province in ascending order
Additionally, let us check some descriptive statistics for the 2019 Elections dataset. More specifically, let us examine the v or votes column. The group will be highly dependent on the votes data so let us first do some initial statistics and visualizations.
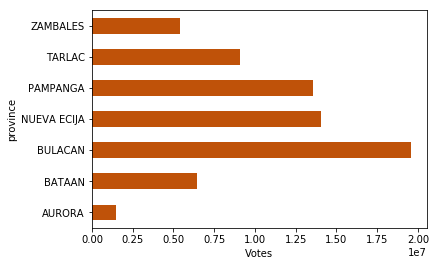
Just to explore, the code and image below shows the total votes in region 3. Notice that Bulacan has the highest number of votes, followed by Nueva Ecija, then Pampanga.
Here we explore the vote distribution in the National Capital Region. The classification of district and cities were broken down by area (Manila, Taguig-Pateros, Second District, Third District, and Fourth District).The top number of votes came from the second district (mainly because of Quezon City), followed by the Fourth District, then the Third District.
FIGURE: Votes Distribution in the National Capital Region
Next, we explore the distribution of votes in Region 4-A. Unsurprisingly, the population of votes is high in the population centers of Cavite, then Batangas, then Laguna.
For now, let us also examine the distribution of election votes in region 7. Unsurprisingly, the votes are concentrated first in Cebu, followed by Bohol and Siquijor.
To match the contestant ID to the contestant name, the contest files were also downloaded from the Commission of Elections’ 2019 National and Local Elections website and stored in the local repository. Similar to the results directory, the contest directory contained json files for each contest type/position. Upon inspection of a sample file within the directory, the following values were obtained:
The pertinent keys from each json files were:
Parameter
Description
cc
Contest code
cn
Contest code name - location
ccc
Contest code name
type
Contest type
bos
list of candidate parameters
Under the bos key, we can extract each of the candidates’ parameters. The more useful ones for the group’s study include:
Parameter
Description
boc
Contestant ID
bon
Contestant Name
pn
Party Name
Step 2: Extract and collect the 2019 Elections (Contestant) data
The group also created utility functions for easier retrieval of the contestant datasets. This is to ensure each dataset is ready for aggregation.
Similar to the get_province_coc, the get_contestant_attrib method unpacks each key and value from the {contest_number}.json dictionary into a cleaned up dataframe. The method converts the bos directory into an additional list, which will also be appended into the resulting dataframe.
There are two (2) major political coalitions fighting for the senate seats:
Hugpong ng Pagbabago (HNP)
Otso Diretso
Similar to the get_all_province_coc, the get_contestants_attrib method is a walker that goes through each of the contest directory. The method will first append all {contest_numer}.json files into a singular dataframe. Next, the method creates a new column that identifies who among the senatorial candidates are part of the Hugpong ng Pagbabago (HNP) or Otso Diretso campaign.
Function for get_contestant_attrib()
def get_contestant_attrib(filepath):""" Returns the contestant json file into a dataframe Parameters ---------- filepath : string Returns ---------- df : pd.DataFrame of contestnat attributes """ contestants_values = []withopen(filepath, 'r') asfile: data = json.load(file) attrib_keys = [key for key inlist(data.keys())ifisinstance(key, (str, float, int))] attrib_values = [value for value inlist(data.values())ifisinstance(value, (str, float, int))] contest_values = [list(contest.values()) for contest in data['bos']] df = pd.DataFrame(contest_values, columns=list(data['bos'][0].keys()))for k, v inzip(attrib_keys, attrib_values): df[k] = vreturn df
We now have two dataframes: df_results containing the 2019 election results, and df_contestants containing the contestant information. These two dataframes can now be merged into a single dataframe. Let us also drop certain columns which we have deemed as unimportant.
We want to find out won across all the regions. If there is any bias for cetain candidates. Based on our findings, we can see that candidate Cynthia Villar won majority of the regions.
It is interesting to note that the top ranking senator for Ilocos Region (Region I) and the Cordillera Administrative Region (CAR) is Imee Marcos, which hails from that region. This confirms that there is a “Solid North”, and that support for the Marcoses still exists in that area.
For the Mindanao regions, the top candidate is Bong Go, former special assistant to President Duterte, who is from Mindanao.
These show that Philippine politics is very regional in nature. Voters will naturally support their hometown candidate, regardless of the issues surrounding that candidate.
Code to get top senator by region and the associated number of votes
Next, let us generate the code to create a map with majority winners.
Code to create a map of majority winners
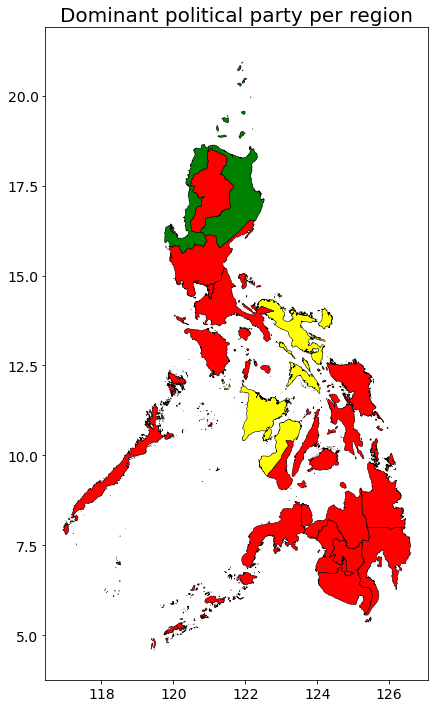
merged = ph0.merge(df_leading_party, left_on='region', right_on='Region')colors =18color_map = {'PARTIDO DEMOKRATIKO PILIPINO LAKAS NG BAYAN': 'red', 'LIBERAL PARTY': 'yellow','NACIONALISTA PARTY': 'green'}fig, ax = plt.subplots(1, 1, figsize = (10,12));ax.set_title('Dominant political party per region', fontsize=20);for party inlist(merged['Party'].unique()): color_map[party] merged[merged['Party'] == party].plot(ax=ax, color = color_map[party], categorical =True, figsize=(10,12), legend=True)merged.geometry.boundary.plot(color=None,edgecolor='k',linewidth =.5,ax=ax);plt.rcParams.update({'font.size': 18})
FIGURE: Top Party by Region
We can clearly see a voting bias of each region.
Majority of Region 1 and Region 2 has a voting preference towards the Nacionalista Party. This can be attributed to the fact that Imee Marcos, who hails from Ilocos Norte, is a Nacionalista.
Majority of Region 5 and Region 6 has a voting preference towards the LIberal Party. This is also expected since Leni Robredo, incumbent Vice President who is from the Liberal Party, is a Bicolano.
The remainder of the Philippines has a voting preference towards the PDP-LABAN.
Step 5: Finding the Dominant Coalition Per Region
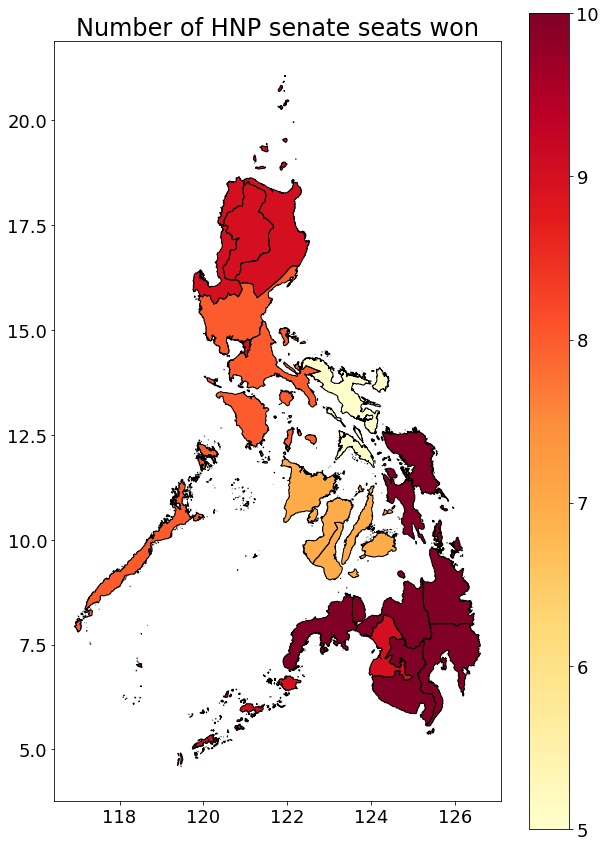
Aside from individual candidates and parties, we also looked at the dominant coalition per region by counting the number of senate seats obtained by each coalition. The results indicate that HNP gained a majority of the seats across all regions, especially in Mindanao.
The only regions where HNP did not gain a solid majority are in Bicol Region (Region V) and Eastern Visayas (Region VI), known bailwicks of the Liberal Party. Below we created a function to get the number of seats won per coalition per region, and the associated map. The more seats won, the darker the color.
Function for get_coalition_sets()
def get_coalition_seats():""" Returns a dataframe of the number of seats won per coalition per region Returns ------- coalition : pd.DataFrame """ coalition_seats = nle2019.query('position == 1') coalition_seats = coalition_seats.groupby( ['region', 'candidate_name', 'coalition'], as_index=False).agg({'votes_per_province': sum}) coalition_seats = coalition_seats.sort_values( by=['region', 'votes_per_province'], ascending=[1, 0]) coalition_seats.set_index('region', inplace=True) coalition_seats['rank'] =list(range(1, len( coalition_seats.candidate_name.unique())+1))\*len(coalition_seats.index.unique()) coalition_seats['is_top_12'] =1*(coalition_seats['rank'] <=12) coalition_seats = coalition_seats.reset_index() coalition_seats = pd.pivot_table( coalition_seats, index='region', columns='coalition', values='is_top_12', aggfunc=np.sum) coalition_seats['coalition_seats_total'] = coalition_seats.sum(axis=1)for coalition in coalition_seats.columns[:-1]: coalition_seats['party_seats_pct_'+ coalition] =\ coalition_seats[coalition] /\ coalition_seats['coalition_seats_total'] coalition_seats.rename( columns={coalition: 'coalition_seats_count_'+ coalition}, inplace=True) coalition_seats = coalition_seats.round(5) coalition_seats = coalition_seats.reset_index()return coalition_seats
Code to merge coalition dataframe and coalition_seat_counts, code to display heat map.
Step 6: Is Demographics Related To Voting Preferences?
Is the voting preference of a region related to its demographics such as literacy rate and religious affiliation? To answer this, we obtained the 2015 Census Data. The directory is a collection of excel files, where each excel file corresponds to a certain region and province. If we explore each file, we can see that each sheet corresponds to a different demographic feature table. For this analysis, we are intrested at sheets T8 and T11.
The get_census_religion loads the imporant columns and rows from sheet T8. It also adds an additional column based on the region. Similarly, the get_census_education loads the imporant columns and rows from sheet T11. It also aggregates each individual years experience column into a singular cumulative column.
Finally, the read_census_files aggregates the 2016 regional data into singular dataframe by using get_census_religion and get_census_education functions. To extract only the regional files, the read_census_files uses regex to get filenames with only underscores in the beginning (this is an indicator of regional data).
Function for get_censis_religion()
def get_census_religion(path):""" Returns a consolidated DataFrame of census data by religion Parameters ---------- path : string, filepath to census directory Returns ---------- df : pd.DataFrame """ filename = os.path.basename(path) df = pd.read_excel(path, sheet_name='T8', header=None, usecols=[0, 1, 2, 3], skiprows=6, skip_blank_lines=True, skipfooter=3, names=['religion', 'total', 'm', 'f']) df.sort_values('total', ascending=False, inplace=True) df['region'] = re.search(r'\_(.*?)\_', os.path.basename(path)).group(1) cols = ['region', 'religion', 'm', 'f', 'total'] df = df[cols]return df
Step 6.1: Is literacy rate related to voting preference?
We looked at the number of seats obtained by each coalition per region, then correlated it to literacy rate. Education information was obtained from the 2015 Census data.
We looked at the literacy rate \(\frac{n_{educated}}{n_{total}}\) of each administrative region:
Function for get_education_percent()
def get_education_percent():''' Gets percentage of educational level per region ''' education = census_dict['education'].groupby( ['region', 'education'], as_index=False).sum() education = pd.pivot_table( education, index='region', columns='education', values='total') education.columns = ['education_pct_'+ educ for educ in education.columns] education['education_total'] = education.sum(axis=1)for educ in education.columns[:-1]: education[educ] /= education['education_total'] education.drop('education_total', axis=1, inplace=True) education = education.round(5)return education
The output table shows the literacy table per region. The main columns shows the percentage that are educated, not_educated and unknown.
region
educated
not_educated
unknown
BARMM
0.85355
0.14105
0.00540
CAR
0.97376
0.02622
0.00002
NCR
0.99234
0.00221
0.00545
NIR
0.98085
0.01882
0.00033
REGION I
0.99321
0.00679
0.00000
REGION II
0.98610
0.01389
0.00001
REGION III
0.99355
0.00615
0.00030
REGION IV-A
0.99473
0.00519
0.00008
REGION IV-B
0.96573
0.03417
0.00010
REGION IX
0.96456
0.03486
0.00058
REGION V
0.99126
0.00851
0.00023
REGION VI
0.98721
0.01257
0.00022
REGION VII
0.98753
0.01209
0.00038
REGION VIII
0.97679
0.02297
0.00024
REGION X
0.98095
0.01856
0.00049
REGION XI
0.97818
0.02050
0.00132
REGION XII
0.94792
0.05034
0.00174
REGION XIII
0.98487
0.01503
0.00010
We then checked if the number of seats obtained by each coalition is correlated to the literacy rate of that region. First, we obtained the number of seats obtained by each coalition per region:
FIGURE: Correlation Matrix between Education and Coalition
The Census and election data show that the voting preference of a region has no correlation with its literacy rate. We now look at religion to see if it has a correlation with the voting preference.
Step 6.2: Is literacy rate related to voting preference?
We also looked into the religious affiliation per region, and checked if it is correlatd with voting preference.
First, we obtained the distribution of religions per region from the Census data:
Function for get_religion_percent()
def get_religion_percent():""" Get percentages of religion per region """ religion = census_dict['religion'].groupby( ['region', 'religion'], as_index=False).sum() religion = pd.pivot_table( religion, index='region', columns='religion', values='total') religion.columns = ['religion_pct_'+ rel for rel in religion.columns] religion['religion_total'] = religion.sum(axis=1)for rel in religion.columns[:-1]: religion[rel] /= religion['religion_total'] religion.drop('religion_total', axis=1, inplace=True) religion = religion.round(5)return religiondf_rel = get_religion_percent()
We then merged the religion census data with the coalition ranking data to check if religion has correlation with the number of seats obtained by each coalition:
Joining the coalition rank dataframe with the output from the get_religion_percent() function.
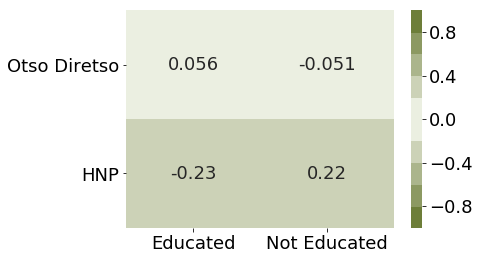
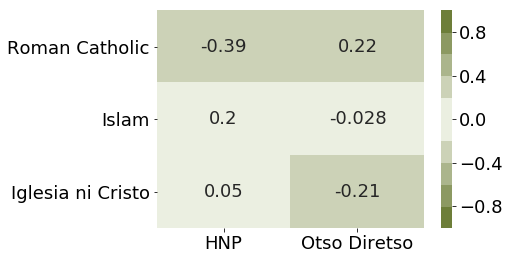
From getting the correlation of the religion data with the number of seats per coalition, it is apparent that the Voting preference of a region has no correlation with its religious affiliation.
Code to get a correlation graph between Religion and Top Coalition Party.
df_coal_rel['Roman Catholic'] = df_coal_rel['religion_pct_Roman Catholic, including Catholic Charismatic']df_coal_rel['Islam'] = df_coal_rel['religion_pct_Islam']df_coal_rel['Iglesia ni Cristo'] = df_coal_rel['religion_pct_Iglesia ni Cristo']corr = df_coal_rel.corr().loc[ ['Roman Catholic','Islam','Iglesia ni Cristo'],['HNP','Otso Diretso']]colormap = sns.diverging_palette(100, 100, n =10)sns.heatmap(corr, cmap=colormap, annot=True, vmin =-1, vmax =1);
FIGURE: Correlation Matrix between Religion and Coalition
Conclusion
Upon checking both the Comelec 2019 Election Results and the 2015 Philippine Census data, we found out that voting preference is characterized by high regionality.
Candidates have a homecourt advantage, and voters tend to vote candidates or parties affiliated with their home region.
Also, literacy rate and religious affiliation is not correlated to voting preference.